From DevTools Detective to Automation Hero: My Quest for Dutch Subtitles
Disclaimer: This content reflects my personal opinions, not those of any organizations I am or have been affiliated with. Code samples are provided for illustration purposes only, use with caution and test thoroughly before deployment.
I’ve been working on improving my Dutch by watching NOS Journaal in Makkelijke Taal (NOS News in Simple Language). It’s perfect for language learners - the vocabulary is accessible, the pronunciation is clear, and the topics are current and relevant.
But here’s the thing: while listening helps with comprehension, I wanted to read the subtitles after watching to catch vocabulary I missed during the video. The built-in video player has subtitles, but constantly pausing to point my phone’s Google Translate camera at the screen proved incredibly disruptive. I’d get tired of watching within minutes.
I already use Readlang extensively for my Dutch studies. It’s a language learning tool where you can import articles, then click on any word or phrase to get AI-powered translations with contextual explanations. The UX is phenomenally smooth, removing most of the friction from reading foreign language content. This would be a great tool to study the subtitles right after I watched the video. However, there is a problem.
Update: The YouTube Alternative I Missed
Edit: After publishing this post and sharing it on the Readlang forum, a helpful reader named WarsawWill_Randomlde pointed out that NOS Journaal in Makkelijke Taal is actually available on YouTube with proper (non-auto-generated) subtitles. You can use YouTube’s “Show transcript” feature to copy the text directly into Readlang, which is much simpler than my automated approach.
However, I have good reasons for sticking with my NPO Start automation. My initial experience with YouTube was watching NOS Jeugdjournaal, where the auto-generated subtitle quality was frustratingly poor - full of transcription errors that made reading more confusing than helpful. This drove me to seek higher-quality subtitles on NPO Start, and I never looked back to check if other NOS programs had better YouTube subtitle quality.
More importantly, the YouTube method still requires several manual steps: opening the video, toggling transcript settings, copying text, switching to Readlang, pasting content, and manually entering titles. While experienced users can do this quickly, my automation reduces the entire process to a single 2-second script execution. For someone who watches daily and values eliminating all friction from the learning workflow, the automation investment was worth it.
That said, the YouTube method has a big advantage: You can play the YouTube video inside Readlang and have the subtitles right beneath the video, with the subtitles synced with the video’s progress. You can see how this can be done in this tutorial. I personally prefer to watch the video once without subtitles to practice my listening comprehension, so I don’t use this feature. But if you prefer to watch the video and read the subtitles at the same time, you should follow this method.
The Problem: Proprietary Video Players
The NPO Start website uses a proprietary video player that makes subtitle extraction far from straightforward. Unlike simple HTML5 video implementations, there’s no obvious way to grab the subtitle files directly. Even if I could access them, they’d be VTT files filled with timestamps and formatting that would need cleaning up before import.
Attempt 1: Inspecting the HTML
My first instinct was to examine the page source. I found a <video> element wrapped in complex third-party video player components, but there was no <track> element pointing to subtitle files. The subtitles were clearly being loaded dynamically, but the loading mechanism wasn’t immediately obvious from the static HTML.
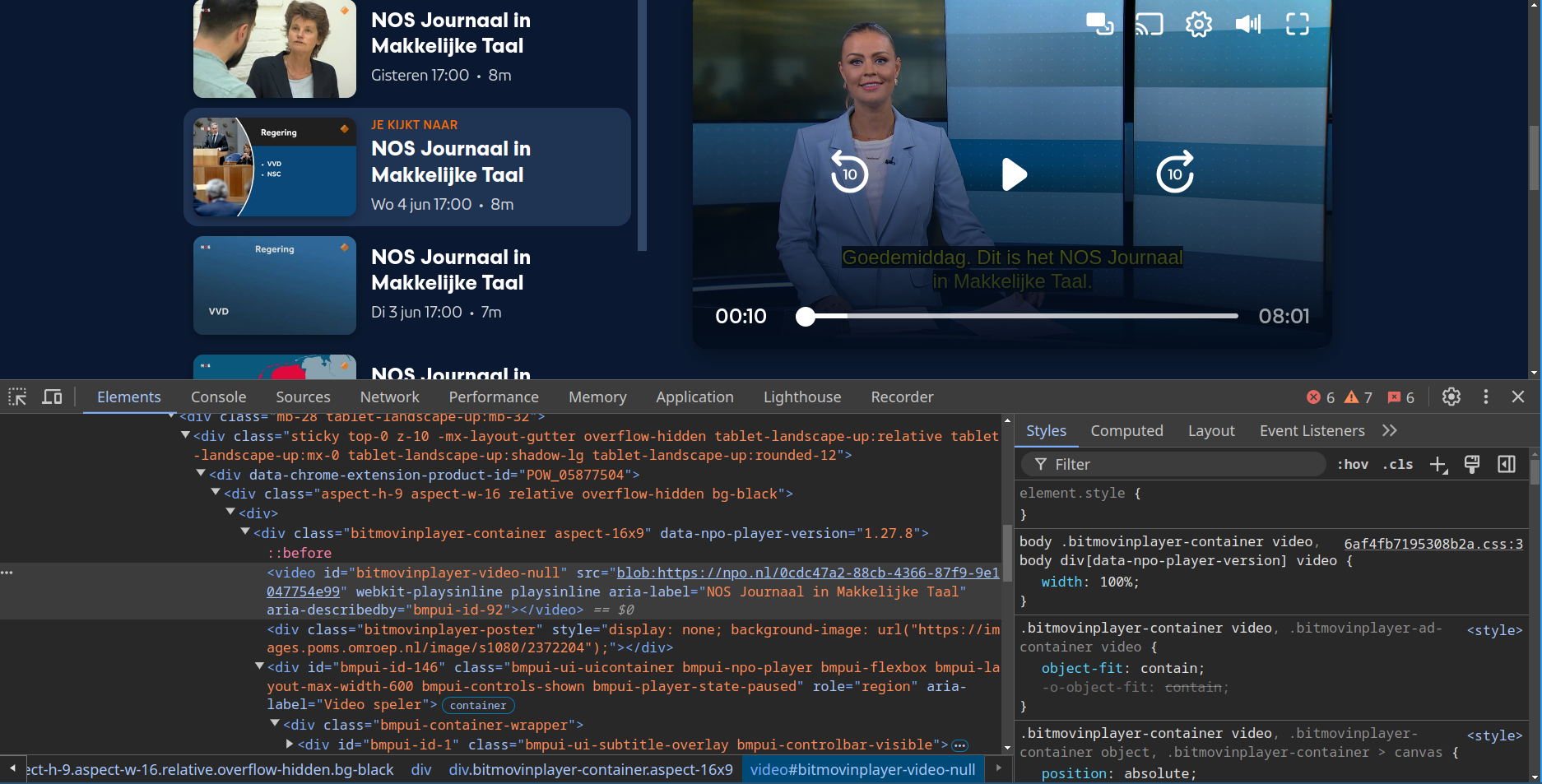
This approach hit a dead end quickly - the subtitle loading was happening entirely through JavaScript, hidden within the video player’s implementation.
Attempt 2: Network Tab Investigation
Since the subtitles had to be downloaded from somewhere, I opened Chrome’s Developer Tools and watched the Network tab while enabling subtitles on the video player.
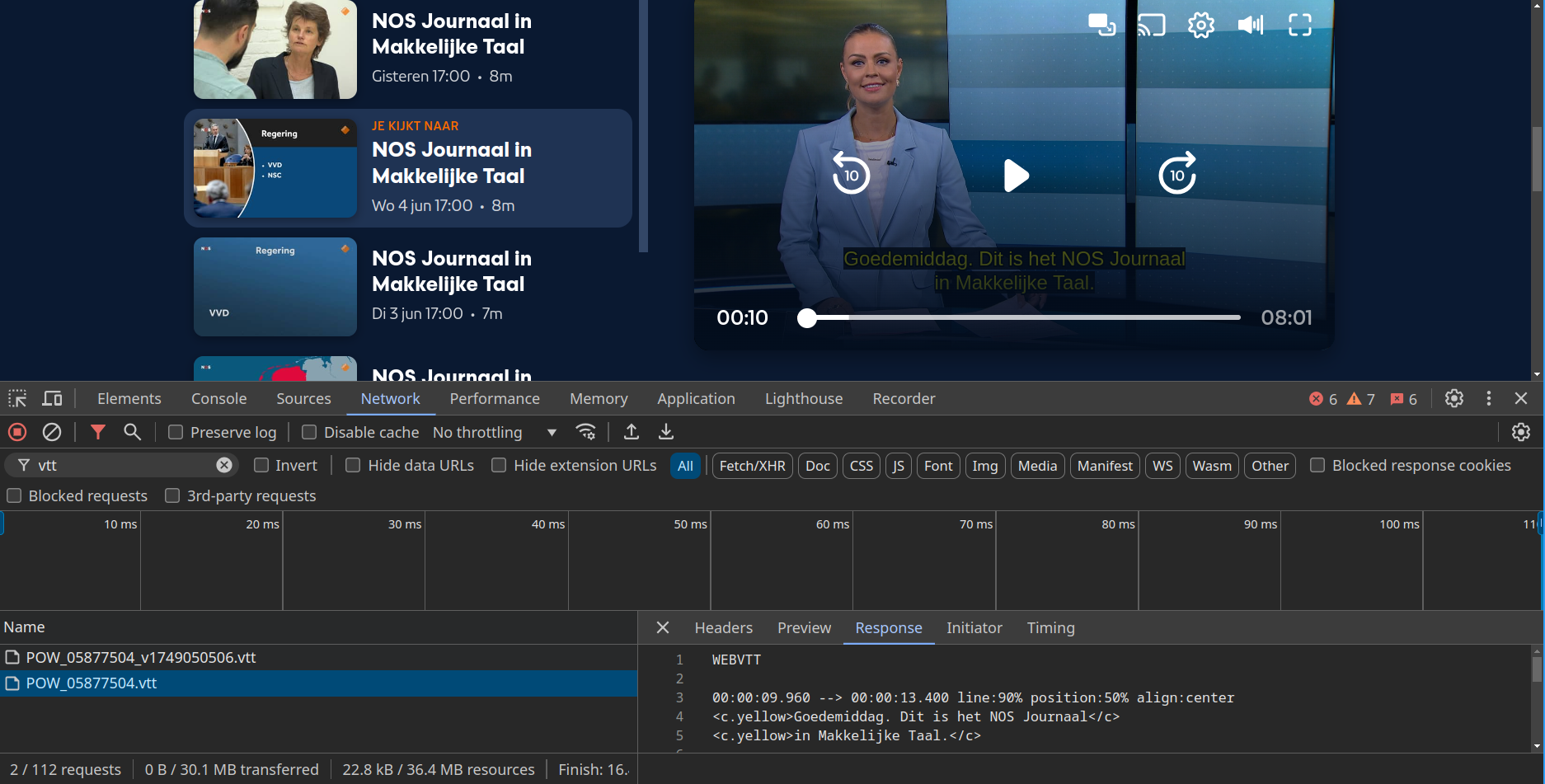
Bingo! I spotted a file called POW_05877504.vtt being downloaded. The response looked exactly like a proper WebVTT subtitle file, complete with timestamps and Dutch text. This was the breakthrough I needed.
The Semi-Automatic Solution
Armed with this knowledge, I built my first working solution: a shell script that automated part of the process while still requiring some manual intervention.
The script would open the NOS Journaal in Makkelijke Taal website, then I’d manually download the VTT file using the Network tab in Developer Tools. Not elegant, but it worked.
Next, I needed to clean up the VTT format. I “vibe coded” a Rust tool that removes timestamps and concatenates lines from the same speaker, transforming the subtitle file into something that reads like a complete article rather than fragmented dialogue snippets.
The final step involved opening Readlang’s file upload page and pasting the cleaned content.
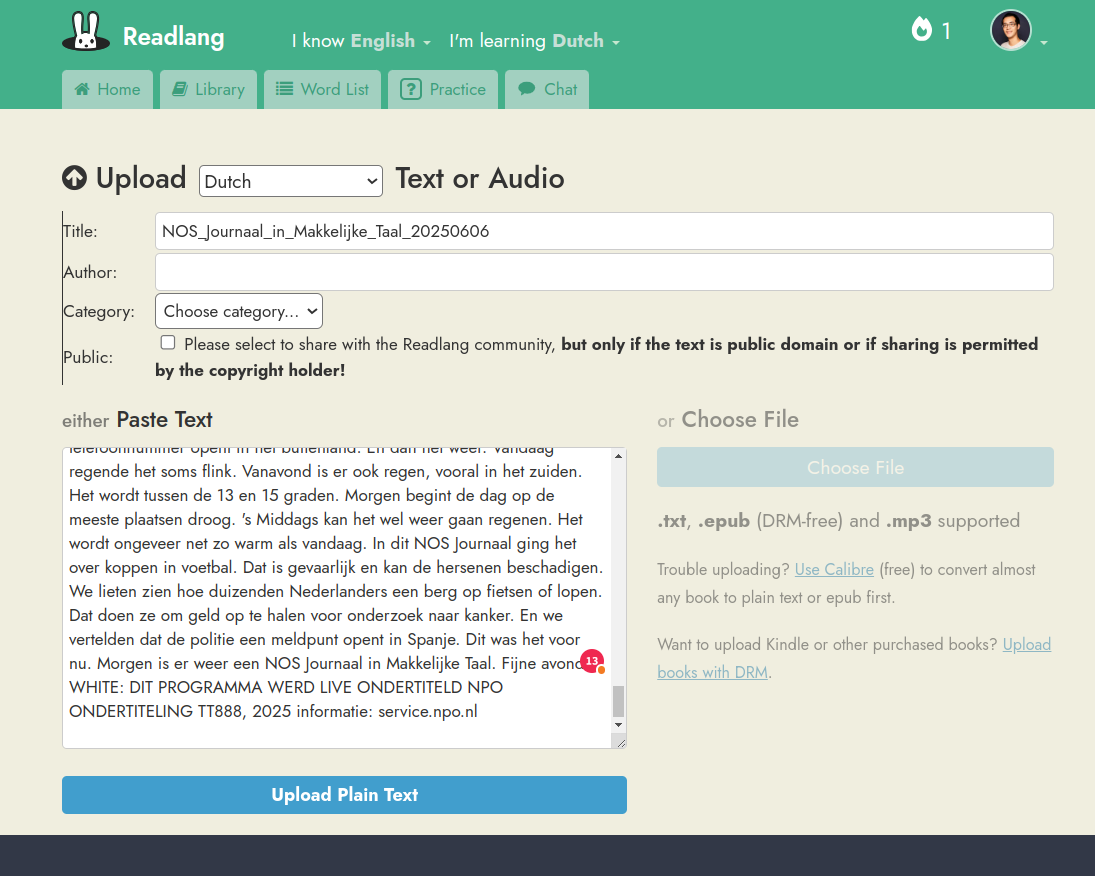
To make the workflow smoother, I added a feature where the script automatically renames the downloaded VTT file to a human-readable format like NOS_Journaal_in_Makkelijke_Taal_20250514. The script waits a few seconds for me to paste the content into Readlang, then copies this readable name to the system clipboard so I can easily paste it as the article title.
I used this approach for several weeks, but the friction remained too high. After a long day, I just wanted to sit down and start watching the news without opening a laptop and fumbling with developer tools.
Attempt 3: The yt-dlp Detour
I discovered that yt-dlp, a popular video downloader CLI tool, has npo.nl support. This seemed promising - if I could extract just the subtitles without downloading the entire video, it would solve my problem elegantly.
Unfortunately, when I instructed yt-dlp to download subtitles only, it returned nothing. The tool’s NPO support apparently doesn’t extend to subtitle extraction, so I abandoned this approach.
Attempt 4: Direct Subtitle Downloads
Rather than wrestling with browser automation tools like Selenium or Playwright (which tend to be slow and flaky), I decided to reverse-engineer the subtitle loading process more thoroughly.
I discovered that VTT files are served from a predictable URL pattern: https://cdn.npoplayer.nl/subtitles/nl/POW_05877504.vtt. The key insight came from examining the HTML more carefully - buried in the page source was a JSON object containing "productId":"POW_05877504".
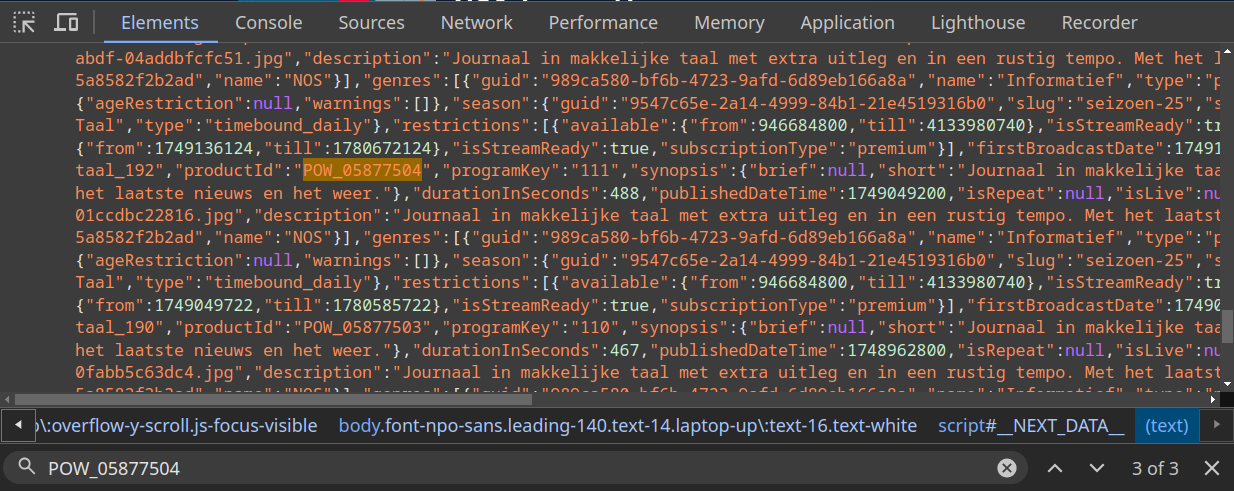
Each video in the series has a unique product ID, and that ID plus .vtt forms the subtitle filename. Perfect!
I wrote another shell script that uses curl to download the HTML source of the video page, then searches for the product ID using regular expressions. Once found, it constructs the subtitle download URL and fetches the VTT file directly.
The rest of the pipeline - cleaning up the VTT file and preparing it for Readlang - remained unchanged. Now I could run a single shell script and have clean subtitles ready for Readlang in under 2 seconds. The whole process became frictionless enough that I actually wanted to use it.
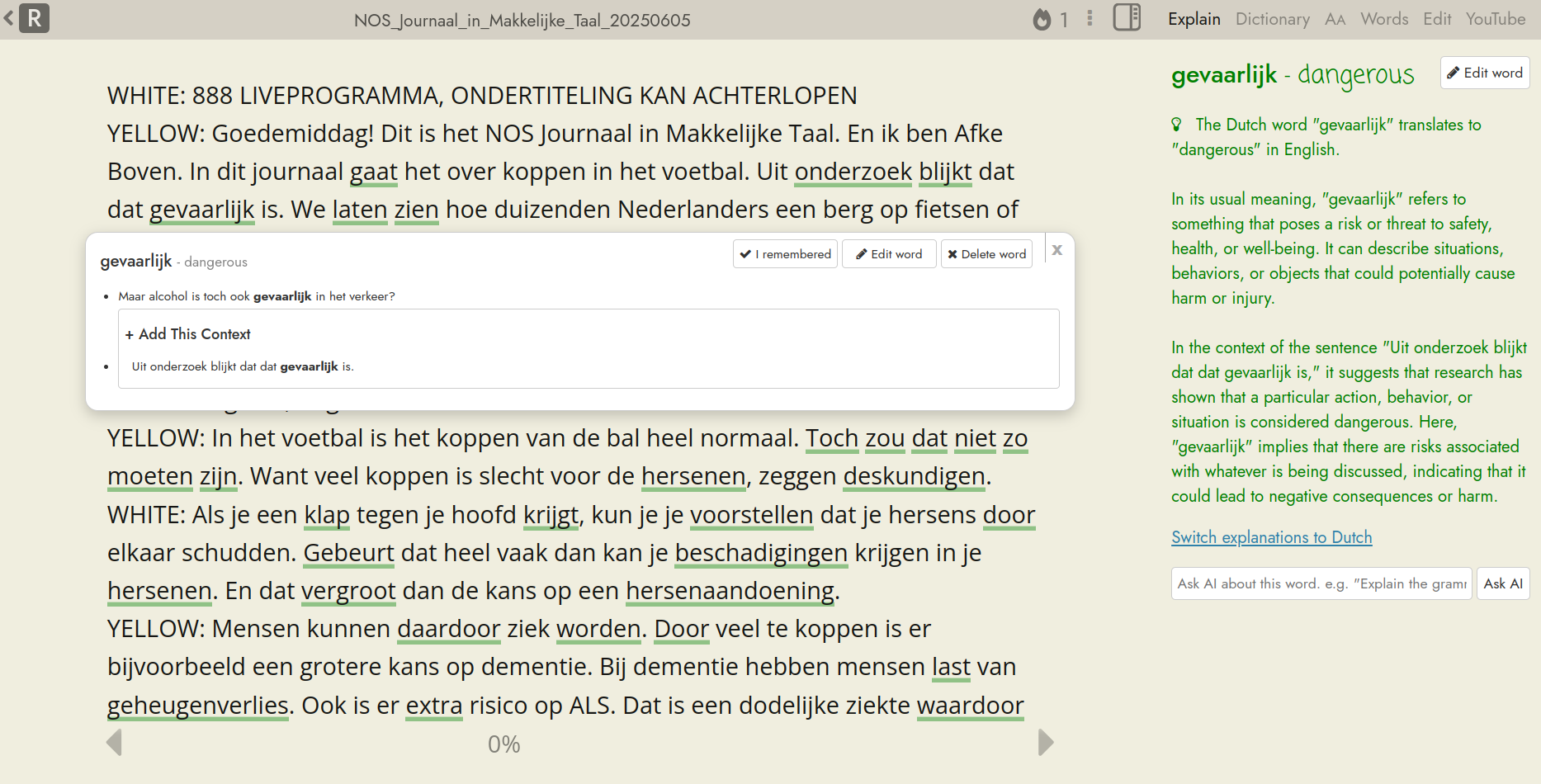
Here is how it looks like to read using Readlang:
Detour: The TamperMonkey Experiment
Before settling on the curl-based solution, I briefly explored adding a “Download subtitle” button directly to NPO.nl pages using a TamperMonkey userscript. The script does the same thing as the shell script, but in JavaScript: it finds the product ID in the page’s HTML, constructs the subtitle download URL, and adds a button that directly downloads the VTT file when clicked.
While this worked, the curl approach proved more reliable and required less browser-specific setup, so I eventually abandoned the userscript approach.
Limitations and Future Work
The current solution works beautifully for my daily news consumption, but there are areas for improvement.
I’d love to automate the Readlang upload process as well, but their API appears to be unsupported. If I could fully automate the entire pipeline, I’d deploy it on a Raspberry Pi with a daily cron job to prepare subtitles automatically.
Additionally, I’ve only tested this approach with NOS Journaal in Makkelijke Taal. Other NPO shows might use different product ID formats or subtitle hosting patterns, so the solution would need testing and potential modification for broader use.
Lessons Learned
This project demonstrates how understanding web technologies, combined with AI-assisted coding, can quickly turn frustrating manual processes into smooth automated workflows.
The investigation phase - figuring out how the NPO website works - required manual detective work that only domain knowledge could provide. But once I understood the underlying patterns, AI tools accelerated the implementation dramatically. The VTT cleanup script took me 1-2 days of iterative prompting, and at one point, when I added too many requirements to Gemini 2.0, it completely broke my working code.
In contrast, I wrote the final download script using Claude 4 Sonnet, and it worked correctly on the first attempt. This reinforces a pattern I’ve observed repeatedly: combining sufficient domain knowledge with AI assistance produces results much faster than either pure manual coding or blind AI prompting without context.
Conclusion
What started as a simple desire to read Dutch news subtitles evolved into a multi-stage automation project that taught me about web scraping, VTT file formats, and the power of combining human investigation with AI-assisted implementation.
The final solution transforms a 5-minute manual process involving multiple browser tabs and developer tools into a 2-second script execution. More importantly, it removed enough friction that I actually use it daily, which was the original goal.
Disclaimer: I download one subtitle per day for personal language learning use and do not redistribute the content. If you plan to use similar methods, always check the terms and conditions and seek appropriate permissions from the video publisher.
