Demystifying The Options for Triggering AWS CodePipeline with Amazon S3 Events
Disclaimer: This content reflects my personal opinions, not those of any organizations I am or have been affiliated with. Code samples are provided for illustration purposes only, use with caution and test thoroughly before deployment.
Triggering AWS code pipeline when new files are uploaded to S3 is a very common use case. For example, when new data is uploaded, you can trigger a CodePipeline that triggers SageMaker model retraining or inference. However, the documentation and services involved in this process have gone through multiple updates, making it confusing for users to understand the current recommended approach. In this post, I will try to untangle the different options and let you know which one is the most up-to-date and recommended approach.
The History
To understand how these services evolved and what is the most up-to-date method, let’s first take a look at the three major components involved in this process: Amazon S3, the trigger mechanism, and AWS CodePipeline, and their respective histories.
Amazon S3:
-
Amazon S3 was launched in 2006, providing object storage services.
-
In 2014, AWS introduced Event Notifications for S3, allowing users to receive notifications when specific events occurred in their S3 buckets. However, these notifications could only be sent to Amazon SNS, Amazon SQS, or AWS Lambda at that time. You can find the announcement post here: New Event Notifications for Amazon S3.
CodePipeline:
-
AWS CodePipeline, a continuous delivery service, was released in 2015. The blog post announcing its release can be found here: Now Available – AWS CodePipeline. Initially, CodePipeline relied on polling to detect changes in S3 buckets.
-
In 2018, CodePipeline introduced support for push-based triggers from Amazon S3, leveraging Amazon CloudWatch Events to receive notifications instead of polling. The blog post announcing this update can be found here: AWS CodePipeline Supports Push Events from Amazon S3.
Trigger mechanism:
-
In 2015, when CodePipeline was first released, it used polling to detect changes in S3 buckets.
-
In 2018, CodePipeline started receiving push-based triggers from S3 via CloudWatch Events.
-
In 2019, AWS launched Amazon EventBridge, replacing CloudWatch Events. The blog post announcing EventBridge can be found here: Introducing Amazon EventBridge. At that time, EventBridge detected S3 changes by parsing CloudTrail trials and using pattern matching and filtering.
-
In 2021, AWS introduced direct integration between S3 Event Notifications and EventBridge, allowing users to receive S3 events directly without the need for CloudTrail logs. This feature is disabled by default and needs to be enabled in the S3 bucket settings. The blog post announcing this update can be found here: New – Use Amazon S3 Event Notifications with Amazon EventBridge.
Putting them together, here is the timeline of the possible combinations:
-
2015: S3 –> CodePipeline polling S3
-
2018: S3 –> CloudWatch Events –> CodePipeline (push-based trigger)
-
2019: S3 –> CloudTrail –> EventBridge (parsing CloudTrail trials) –> CodePipeline
-
2021: S3 –> EventBridge (directly receiving S3 Event Notifications) –> CodePipeline
Mixed document versions
Due to the various updates, the documentation and AWS Console have different versions:
-
The CodePipeline documentation on creating a CodePipline with S3 source action uses the 2019 method, asking you to create CloudTrail trials: Amazon S3 source actions and EventBridge with AWS CloudTrail - AWS CodePipeline.
-
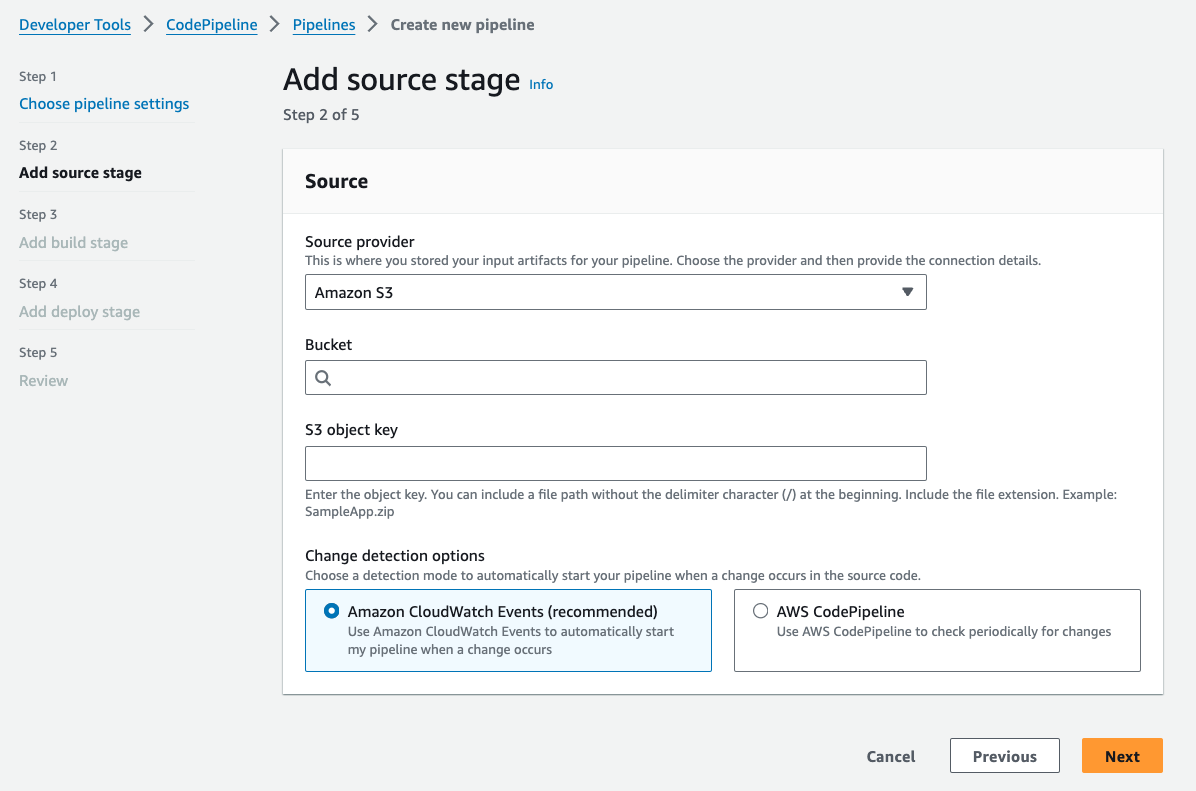
The CodePipeline create wizard in the AWS Console still references CloudWatch Events (2018 method).
-
The EventBridge rule creation wizard shows options for both CloudTrail-based (2019) and direct S3 Event Notification (2021) methods.

-
CodePipeline documentation has a guide on migrating from polling (2015) to EventBridge with Event Notification (2021, recommended) and EventBridge through CloudTrail trail (2019): Migrate polling pipelines to use event-based change detection - AWS CodePipeline.
-
Some older posts might reference the 2018 method using CloudWatch Events, such as Customizing triggers for AWS CodePipeline with AWS Lambda and Amazon CloudWatch Events.
Conclusion
If you don’t have any legacy setup (e.g. has polling pipeline, still using CloudWatch Events), the recommended approach is to use the 2021 method:
-
Enable S3 Event Notifications for EventBridge in the S3 bucket settings
-
Create an EventBridge rule to trigger CodePipeline on S3 changes.
The documentation for this approach can be found here: Migrate polling pipelines to use event-based change detection - AWS CodePipeline.
