How Many Models Can You Fit into a SageMaker Multi-Model Endpoint?
Disclaimer: This content reflects my personal opinions, not those of any organizations I am or have been affiliated with. Code samples are provided for illustration purposes only, use with caution and test thoroughly before deployment.
Recently, I’ve been working on a project that requires running thousands of models simultaneously. To save costs, we decided to run it on a SageMaker Multi-Model endpoint.
Here is the official definition of Multi-Modal Endpoint from the official AWS Documentation:
Multi-model endpoints provide a scalable and cost-effective solution to deploying large numbers of models. They use the same fleet of resources and a shared serving container to host all of your models. This reduces hosting costs by improving endpoint utilization compared with using single-model endpoints. It also reduces deployment overhead because Amazon SageMaker manages loading models in memory and scaling them based on the traffic patterns to your endpoint.
Some example use cases include:
-
House price estimation models for different cities
-
Machine anomaly detection algorithms for different machine configurations
These use cases have many models, with the same model algorithm and framework but trained on different dataset.
A key questions aries: “How many models can we fit into one instance, and what instance type do we need?”. This post demonstrates my experiment results to answer this quesetion.
Benchmarking
To explore this question, I conducted an (incomplete) benchmarking exercise using a notebook from the blog post Save On Inference Cost By Using Amazon SageMaker Multi-Model Enpoint. I copied the 3 XGBoost models in the notebook 3000 times (1000 times each), named them from 0000.tar.gz to 3000.tar.gz. Then I created a Multi-Model endpoint, and copied those models into it. Then, I tried two approaches:
-
Running 1 invocation per model sequentially (0000, 0001, …, 3000)
-
Invoking random models, with some models being repeated multiple times
The results I got are interesting:
-
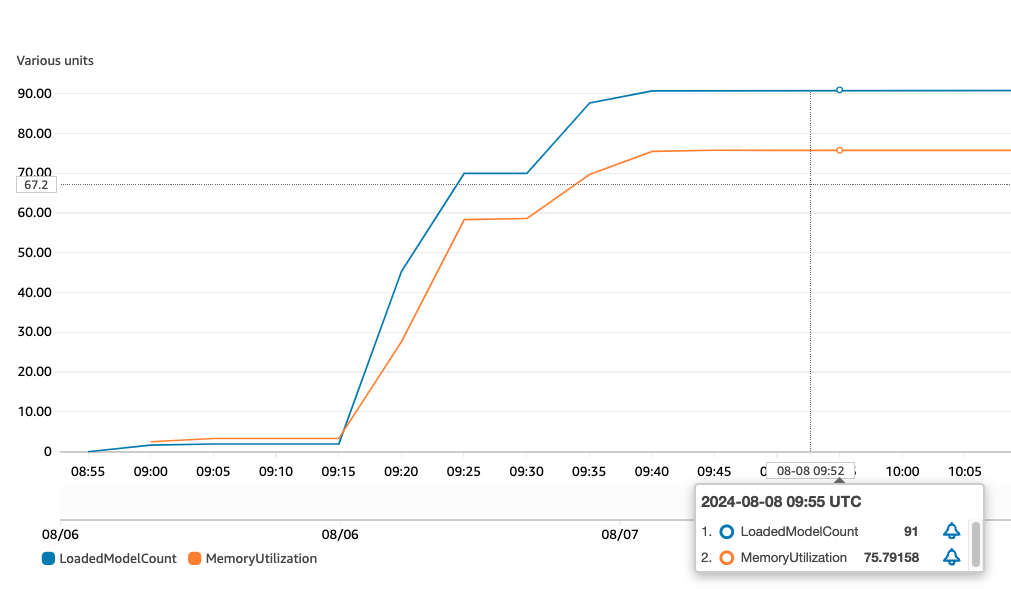
I started with the instance type used in the blog post: ml.m4.xlarge (4CPU, 16GiB memory)
-
When the model is invoked for the first time, the latency is about 1.3-1.5 seconds
-
Once the model is loaded into cache, repeated call latency is below 50 ms.
-
When the instance memory utilization reaches around 75% to 80%, the endpoint starts to unload models. The total number of XGBoost models that can fit into memory at the same time is about 91-92.
Things to consider when designing the endpoint
The way multi-model endpoint works is that it stores the model artifacts in a S3 bucket, and when you call a specific model, the inference container would load the model from S3 into memory. When the instance runs out of memory, it will unload less frequently used models to make room for the new one. Since the model artifacts are stored on S3, you can hold virtually an unlimited number of models. The bottleneck is how many models you can fit into memory. Models in memory are 50x - 100x faster than those that need to be loaded from S3. If cold start latency is not a concern, you can use a small instance and fit as many models as you want.
But if the latency is indeed a concern, you need to consider how many models will be used simultaneously. Sometimes there are traffic patterns you can estimate. For example, imagine a global video streaming app with video recommendation models per country. The users mostly use the app after work from 6 PM to midnight, then only about 1/4 of the models are active at a time. In this case, you only need an instance type that can fit about 1/4 of the models.
Also consider the CPU/memory ratio in the instance type you choose. Since XGBoost inference runs on CPU, and the models in the example notebook are lightweight compared to deep neural networks, memory-optimized instances with a higher memory-to-CPU ratio may be more suitable. I tried the ml.r5.xlarge (4 CPU, 32 GiB memory) instance, which held about 210 models in memory with comparable inference performance to the ml.m4.xlarge. Notice that ml.r5.xlarge provides double the memory with the same number of CPUs as ml.m4.xlarge.
You can auto-scale the endpoint horizontally, which creates more instances for you if the traffic increases and it has built-in load balancing. However, there doesn’t seem to be a way to control the load balancing algorithm, so you can’t guarantee that an instance will cache different models. Based on the random routing, each instance will cache models that they receive requests on. And the same model might be cached on different instances. The scaling makes more sense if your bottleneck is CPU or GPU. If you want to scale horizontally and ensure that each instance caches a non-overlapping subset of the models, you might need to manually partition the models into groups, deploy separate endpoints, and build a partition-aware load balancer that routes the model to the instance that caches it.
Conclusion:
In summary, the Multi-Model endpoint on SageMaker is a cost-effective solution for deploying a large number of models, especially when the models are small and have similar algorithms and frameworks. The key factor to consider is not how many models you put in one endpoint, but instead how many models can be loaded into the instance memory simultaneously. Choosing the right instance type with an appropriate CPU/memory ratio is crucial for optimal performance and cost-effectiveness. Additionally, understanding the usage patterns and the number of active models at any given time can help in selecting the right instance size and scaling strategy.
