Building a Fast and Accurate Transcription Tool on Linux
Disclaimer: This content reflects my personal opinions, not those of any organizations I am or have been affiliated with. Code samples are provided for illustration purposes only, use with caution and test thoroughly before deployment.
As a developer, I often find myself needing a tool that can let me type with voice. While macOS boasts a variety of excellent GUI-based transcription tools, the Linux landscape leans more towards command-line utilities. This presented a challenge, but also an opportunity to build a custom solution tailored to my workflow. I kept delaying it, but now I finally got time to build a fast and accurate transcription tool on Linux, leveraging the power of command-line tools and the flexibility of the terminal. I used VSCode, Cline, Gemini 2.0 Flash (in Plan Mode), and Gemini 2.0 Pro (in Act Mode) to help me build this.
Why Whisper and Faster Whisper?
When it comes to transcription accuracy, Whisper models from OpenAI consistently outperform many other options. Initially, I experimented with whisper.cpp, a C++ implementation of the Whisper architecture. It’s a fantastic project, offering great performance and flexibility, especially on my work Macbook with Apple silicon.
However, I recently discovered Faster Whisper, a reimplementation of the Whisper model using CTranslate2. The key advantage? It’s incredibly fast, even on older hardware without dedicated GPUs. On my trusty old laptop with an Intel Core i5-7200U CPU, the small.en model loads in about 2 seconds and can transcribe 1-3 sentences in roughly 4 seconds. This makes it perfectly suited for my needs.
Building the Transcription Tool: Code Examples in transcribe.py
You can find the full source code for WhisperNow (just a random placeholder name for this project) on GitHub: https://github.com/shinglyu/WhisperNow
Let’s dive into the code and see how it all comes together. The core of the tool is a Python script, transcribe.py.
Loading the Whisper Model in Python
First, we need to load the Whisper model. We’ll use the faster-whisper library for this:
from faster_whisper import WhisperModel
model_size = "small.en"
model = WhisperModel(model_size, device="cpu", compute_type="int8")
segments, info = model.transcribe(
"audio.wav",
beam_size=2,
language="en",
vad_filter=True,
vad_parameters=dict(min_silence_duration_ms=500)
)
This snippet initializes the WhisperModel with the specified size (small.en), device (cpu), and compute type (int8). The transcribe method then processes the audio file (“audio.wav” in this example, but we’ll use a temporary file in the full script) and returns the transcribed segments. The vad_filter and vad_parameters help to filter out silence, improving accuracy and speed.
Addressing the Model Loading Latency
A key challenge is the model loading time. Even with Faster Whisper, loading the small.en model takes around 2 seconds. This delay is noticeable if you want to start transcribing quickly. My ideal workflow is to begin recording immediately and have the model ready to go when the recording stops.
Background Recording and Parallel Model Loading
To achieve this, I use a background process for audio recording. I chose sox for its simplicity. The recording starts in a separate thread, allowing the model to load concurrently. This part is written by the AI, so it seems a little overcomplicated, but it works great, so I don’t bother cleaning it up.
import subprocess
import threading
import os
RECORDING_PATH = "/tmp/recordings"
RECORDING_FILE = os.path.join(RECORDING_PATH, "recording.wav")
os.makedirs(RECORDING_PATH, exist_ok=True)
def record_audio():
global sox_process
print("Recording...")
try:
sox_process = subprocess.Popen(
["sox", "-d", "-r", "16000", "-c", "1", "-b", "16", RECORDING_FILE],
stderr=subprocess.DEVNULL, # Suppress "sox WARN" messages
)
sox_process.wait() # Wait for the process to finish
except subprocess.CalledProcessError:
print("Recording stopped.")
except KeyboardInterrupt:
print("Recording stopped.")
recording_thread = threading.Thread(target=record_audio)
recording_thread.start()
Here’s how we stop the recording thread:
# Example of stopping the recording (this would typically be in your main loop)
if sox_process:
sox_process.terminate()
try:
sox_process.wait(timeout=5) # Wait for the process to terminate with a timeout
except subprocess.TimeoutExpired:
sox_process.kill() # Forcefully kill if it doesn't terminate
recording_thread.join()
The record_audio function uses sox to record from the default audio input device (-d) at a sample rate of 16kHz, mono channel (-c 1), 16-bit depth (-b 16), and saves it to RECORDING_FILE. This combination of sample rate, channel and depth works best for Whisper. The recording runs in a separate thread (recording_thread), allowing the main script to continue execution. The stopping mechanism uses sox_process.terminate() for a graceful shutdown and sox_process.kill() as a fallback.
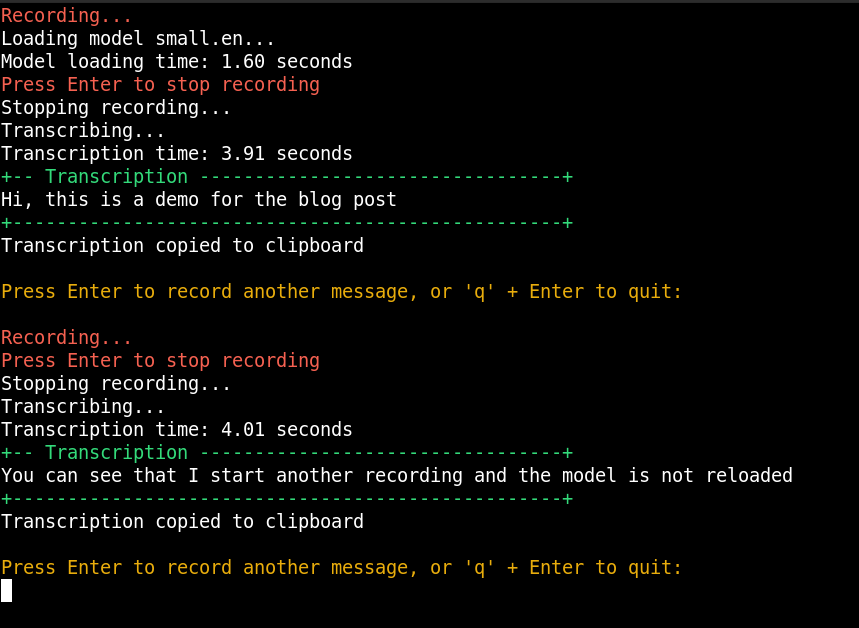
Transcription more than once with a Model in Memory
To avoid reloading the model for every transcription, I use a while True loop. This keeps the model loaded in memory, ready to process new recordings.
while True:
if recording_thread is None or not recording_thread.is_alive():
recording_thread = threading.Thread(target=record_audio)
recording_thread.start()
# Load the model *after* starting the recording thread
if 'model' not in locals():
print(f"Loading model {model_size}...")
start_time = time.time()
model = WhisperModel(model_size, device="cpu", compute_type="int8")
end_time = time.time()
print(f"Model loading time: {end_time - start_time:.2f} seconds")
if input("Press Enter to stop recording"):
break
if recording_thread and recording_thread.is_alive():
print("Stopping recording...")
try:
# Terminate the sox process gracefully
if sox_process:
sox_process.terminate()
sox_process.wait()
recording_thread.join()
except Exception as e:
print(f"Error stopping recording: {e}")
print(f"Transcribing...")
start_time = time.time()
segments, info = model.transcribe(
RECORDING_FILE,
beam_size=2,
language="en",
vad_filter=True,
vad_parameters=dict(min_silence_duration_ms=500) # Remove silence that is longer than 500ms
)
transcription = " ".join([segment.text.strip() for segment in segments])
transcription = transcription.strip()
end_time = time.time()
print(f"Transcription time: {end_time - start_time:.2f} seconds")
print(f"+-- Transcription {'-' * 33}+")
print(transcription)
print(f"+{'-' * 50}+")
subprocess.run(["wl-copy", transcription])
print(f"Transcription copied to clipboard")
print("")
print("Press Enter to record another message, or 'q' + Enter to quit: ")
read_list, write_list, error_list = select.select( [sys.stdin], [], [], TIMEOUT_SECONDS )
if (read_list):
if sys.stdin.readline().strip().lower() == 'q':
break
else:
print(f"\nNo input received within {TIMEOUT_SECONDS} seconds. Exiting.")
break
This loop continuously checks for user input. It starts a new recording if one isn’t already running, loads the model (only once), waits for the user to press Enter to stop recording, transcribes the audio, prints the transcription, copies it to the clipboard (using wl-copy), and then prompts for another recording or exit. The select call adds a timeout, so the script exits automatically if there’s no input for a defined period (TIMEOUT_SECONDS).
Hotkey Integration with Sway
The final piece of the puzzle is hotkey integration. My goal is to be able to trigger transcriptions with a simple key combination, without having to manually open a terminal and run commands. Since this is a terminal-based application, I need a UI, which in this case is the terminal itself. I use the Sway window manager, which allows me to define custom keybindings. I configured Ctrl+Shift+Space to execute a script that launches the transcription process.
Shell Script for Terminal Integration (run_in_terminal.sh)
To make the hotkey work, I created a simple shell script, run_in_terminal.sh, that opens a new terminal window and executes the Python script:
#!/bin/bash
# Define the path to the script
# Find the scirpt in the same folder as this script
SCRIPT_PATH="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
# Open a new terminal and source the script
gnome-terminal -- bash -c "OMP_NUM_THREADS=4 uv run ${SCRIPT_PATH}/transcribe.py"
# In gnome-terminal Edit > Preference > Command > When command exists: Exit the teriminal"
This script determines its own location (SCRIPT_PATH) and then uses gnome-terminal to open a new terminal window and run transcribe.py. The OMP_NUM_THREADS=4 environment variable is set to limit the number of threads used by the Whisper model, optimizing performance. I also set the gnome-terminal preference to exit the terminal when the command exists. Now, whenever I need to transcribe something, I simply press the hotkey. A new terminal window pops up, the recording starts immediately, and the Whisper model loads in the background. Once I’m done speaking, I press Enter, the recording stops, and the transcription appears almost instantly. The transcribed text is also automatically copied to my clipboard, ready to be pasted wherever I need it.
Simplified Dependency Management with uv
One of the key features that makes this project easy to distribute and run is the uv tool. uv is a fast and efficient package manager for Python. It simplifies the process of managing dependencies, especially for single-file scripts like transcribe.py.
Whisper model
If you look at the beginning of transcribe.py, you’ll see the following comments:
# /// script
# requires-python = ">=3.12"
# dependencies = [
# "faster-whisper"Whisper model
# ]
# ///
These comments are not just for documentation; uv uses them to automatically install the required dependencies. The requires-python line specifies the minimum Python version, and the dependencies list specifies the required packages.
When you run the script using uv run transcribe.py, uv automatically installs the specified dependencies (in this case, faster-whisper), and then executes the script within that environment. This eliminates the need for manual virtual environment management and ensures that the script always runs with the correct dependencies, regardless of the user’s system configuration. This is a game-changer for distributing simple Python applications, as it removes a significant barrier to entry for users who may not be familiar with Python packaging.
The Caveat of Streaming Transcription
I also tried a method used in https://github.com/mldljyh/whisper_real_time_translation to speed up the transcription. It uses a Python library called speech_recognition to record the audio in the background. Whenever the user paused or a certain timeout is reached, the partial recording will be sent to the main thread for transcription. This sounds great in theory, because after you finish each sentence, the transcription will start in parallel. So you don’t have to wait a long time at the end for the transcription to run. But actually it doesn’t work that well. The main reason is that your transcription will be more accurate if you send a longer recording. The Whisper model then can look at the context and figure out what word you are actually saying and where the punctuation should be. If you send sentence by sentence, the model has too little context to disambiguate words. Also if you are thinking and paused in between sentences, the punctuation will not be correct and you will have to spend a lot of time manually fixing the key words and punctuation. So I decided to keep the transcription at the end on the full recording.
The speech_recognition library also provide native integration with Faster Whisper. So you can use its built-in method to very easily handle the background recording and live transcription. But upon inspecting its code, I noticed that it loads the FasterWhisper model every time you run a transcription on a single sentence (see https://github.com/Uberi/speech_recognition/blob/6fec47e648238f2fdcf1411071b2c0eaf6a68a16/speech_recognition/recognizers/whisper_local/faster_whisper.py#L83). So it’s quite inefficient. Also the maintainer is looking for someone to take over their role, and there are a lot of old pull requests accumulating. So I don’t want to bet on this library.
Future work: OpenAPI Server Alternative (and Why Not in This Case)
It’s worth noting that you could launch an OpenAPI-compatible server for Whisper. This would offer a cleaner separation between the server (handling the model) and the client (handling recording and user interaction). The model would also always be “hot”, eliminating the loading time on subsequent transcriptions.
However, for my specific workflow, a local, command-line approach is preferable. It avoids the overhead of managing a separate server, provides a simpler setup for personal use. This is because I want to trigger it from Sway, which I’ll show next.
Conclusion
This project demonstrates the power and flexibility of building custom solutions on Linux. By combining Faster Whisper, sox, and a bit of Python scripting, I’ve created a fast, accurate, and convenient transcription tool that seamlessly integrates into my workflow. The benefits include:
- Speed: Faster Whisper provides near real-time transcription, even on modest hardware.
- Accuracy: Whisper models are known for their high accuracy.
- Linux Integration: The tool is built entirely with command-line tools, making it a natural fit for the Linux environment.
- Hotkey Convenience: The hotkey integration allows for on-demand transcription with minimal interruption to my workflow.
I encourage you to adapt and customize this tool to your own needs. You could experiment with different Whisper models, recording parameters, or even integrate it with other applications. The possibilities are endless!
